
"Little by little, we gave you everything you ever dreamed of …"
— Little by Little, Oasis
Continual learning (CL) with large pre-trained models aims to incrementally acquire knowledge without catastrophic forgetting. Existing LoRA-based Mixture-of-Experts (MoE) methods expand capacity by adding isolated new experts while freezing old ones, but still suffer from redundancy, interference, routing ambiguity, and consequent forgetting.
We investigate the issues stemming from coarse-grained expert granularity. Coarse-grained experts (e.g., high-rank LoRA) encode low-specialty information, leading to expert duplication/interference and routing degradation/confusion as experts accumulate.
In this work, we propose MoRAM (Mixture of Rank-1 Associative Memory). Grounded in the view that weight matrices act as linear associative memories, MoRAM achieves CL as incremental expansion of reusable atomic rank-1 experts as memory. Each rank-1 adapter acts as a fine-grained MoE expert or an associative memory unit.
By viewing rank-1 experts as key–value memory pairs, we eliminate explicit MoE-LoRA routers with self-activation, where each memory atom evaluates its relevance via its intrinsic key. The inference process thus becomes a content-addressable retrieval and recall over the incrementally accumulated memory of learning snapshots.
Extensive experiments on CLIP and LLMs show that MoRAM significantly outperforms state-of-the-art methods, achieving a better plasticity–stability trade-off, stronger generalization, and reduced forgetting.
Top — MoE-LoRA. Adding a new rank-\(r\) expert per task is convenient, but the expert is treated as an indivisible block. Three coupled pitfalls follow: (①) intra-expert inter-rank interference — within an expert, only a few of the \(r\) ranks match the input while the rest co-fire as noise; (②) inter-expert redundancy — to mask ①, the router learns to co-activate a duplicate expert on the same input, wasting capacity; (③) routing collapse — at inference, overlapping experts and an external router make routing ambiguous, driving catastrophic forgetting on prior tasks.
Bottom — MoRAM. Each task appends \(r\) rank-1 atoms to the memory bank little by little; the LoRA update is reframed as a linear associative memory \(\Delta\mathbf{W}=\sum_{i}w_{i}\mathbf{B}_{i}\mathbf{A}_{i}^{\top}\) where each atom is a key–value entry. Self-activation \(s_{i}=\mathbf{A}_{i}\!\cdot\!\mathbf{x}\) scores every atom in parallel; a sparse top-\(k\) mask keeps only the most relevant; threshold pruning \(s_{i}\!\geq\!\delta\) drops the weakest survivors. The surviving sparse mixture mitigates each pitfall one-for-one: (①) per-atom specialization — rank-1 atoms either fire or stay silent, eliminating within-expert noise; (②) knowledge reuse — atoms learned on earlier tasks re-fire on related new inputs, so no duplicate experts are needed; (③) forgetting mitigation — frozen \(\mathbf{A}_{i},\mathbf{B}_{i}\) keep prior atoms reachable by their own keys, so capacity grows without rewriting old memory.

Figure 1. Animated comparison of MoE-LoRA pitfalls vs. MoRAM solutions. See the paper for full analysis.
Each new task freezes all earlier rank-1 atoms and adds \(r\) new ones. A sparse self-activated mixture over the full bank sets input-dependent weights so only a few ranks activate at once. Figure 2 sketches growth from task \(t\) to \(t+1\): (a,c) conceptually, (b,d) the mixture computation. §3.2–§3.3 fill in the math.
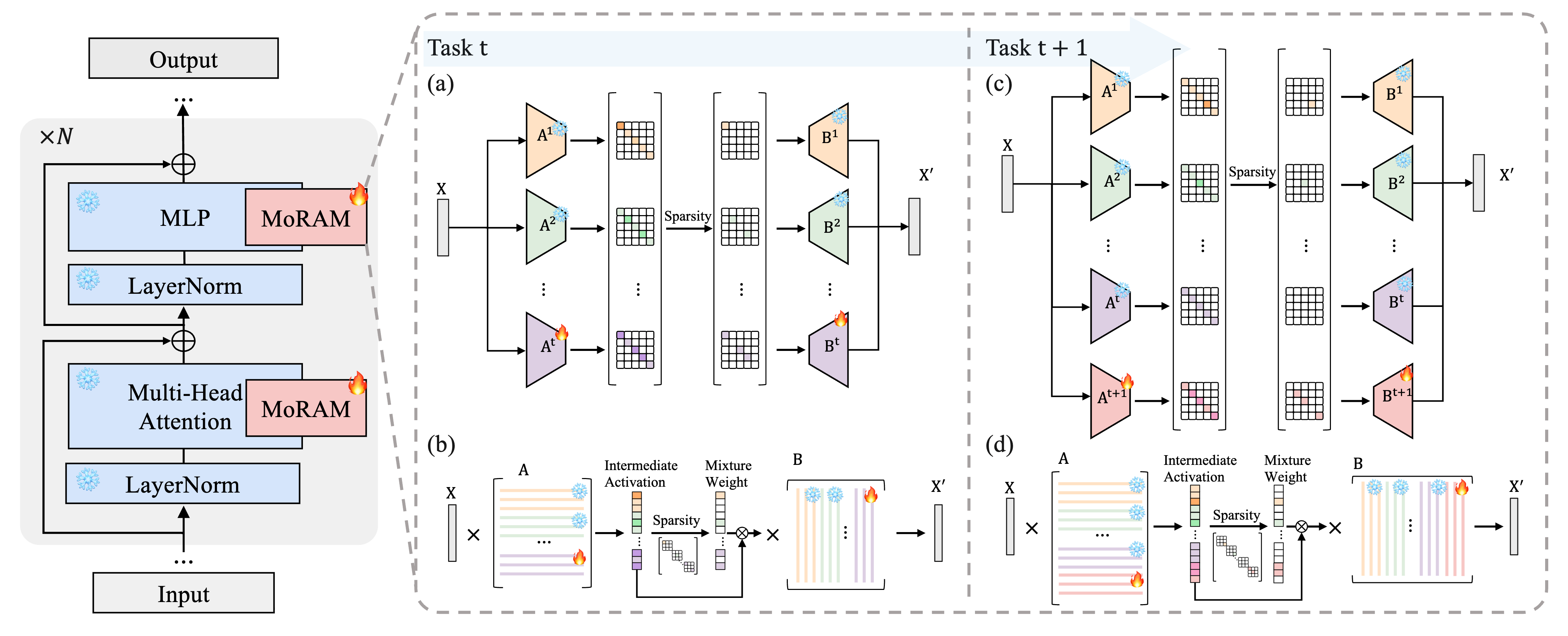
Figure 2. Freeze past ranks, add \(r\) new ranks, sparse mixture over all atoms. (a,c) overview; (b,d) tasks \(t\) and \(t+1\).
To mitigate the coarse granularity and routing ambiguity of dense rank-\(r\) updates, the paper reframes LoRA not as monolithic blocks but as a linear associative memory over the weight matrix.
Definition 1 (informal). A matrix \(\mathbf{W}\in\mathbb{R}^{d_{\text{out}}\times d_{\text{in}}}\) of rank \(m\) is viewed as \(m\) atomic key–value pairs \(\{(\mathbf{k}_{i},\mathbf{v}_{i})\}_{i=1}^{m}\) with \(\mathbf{k}_{i}\in\mathbb{R}^{d_{\text{in}}}\), \(\mathbf{v}_{i}\in\mathbb{R}^{d_{\text{out}}}\), and \(\mathbf{W}\approx\sum_{i=1}^{m}\mathbf{v}_{i}\mathbf{k}_{i}^{\top}\). For a hidden state \(\mathbf{x}\), the product \(\mathbf{W}\mathbf{x}\) acts like a content-addressable read: each inner product \(\mathbf{k}_{i}^{\top}\mathbf{x}\) scores relevance to slot \(i\) and gates the retrieved value \(\mathbf{v}_{i}\).
Remark. Unlike self-attention—where keys and values are dynamic functions of the input—here \(\mathbf{k}_{i}\) and \(\mathbf{v}_{i}\) are static parameters of the matrix, encoding patterns acquired during pre-training.
Fine-grained rank-1 memory augmentation. The low-rank update \(\Delta\mathbf{W}\) is not one rank-\(r\) slab but a sum of \(r\) rank-1 key–value pairs: row \(\mathbf{A}_{i,:}\) acts as the Key (relevance to the input) and column \(\mathbf{B}_{:,i}\) as the Value (stored correction). Adaptation becomes memory expansion—a flexible set of atoms rather than a single rigid adapter.
Standard LoRA (and MoE-LoRA at the adapter level) still densely mixes rank-1 components, which encourages interference on mismatched inputs and routing collapse by ignoring the natural role of \(\mathbf{A}\) as content-based retrieval keys in favor of indiscriminate activation or extra routers.
MoRAM formulation. Adaptation parameters are a growing set of atoms \(\mathcal{M}_{t}=\{(\mathbf{B}_{:,i},\mathbf{A}_{i,:})\}_{i=1}^{r_{t}}\). For task \(t\), the effective update is a sparse, input-dependent mixture with weights \(\mathrm{w}_{i}\in\mathbb{R}\) (retrieval confidence for atom \(i\)):
This lets the model freeze old atoms for stability while adding new ones for plasticity, or combine several memories when concepts overlap—without an auxiliary router module.
Mixing weights come from each rank-1 adapter’s own key \(\mathbf{A}_{i,:}\), not from a separate MoE router over \((\mathbf{A}_{i,:},\mathbf{B}_{:,i})\) pairs—routing is content-addressable retrieval over static memory keys, which avoids extra router parameters and the forgetting they can introduce.
Self-activated relevance scoring. For hidden state \(\mathbf{x}\in\mathbb{R}^{d_{\text{in}}}\) and \(r_{t}\) accumulated atoms after task \(t\), the raw score \(s_{i}\) for atom \(i\) is the key response \(\mathbf{A}_{i,:}\mathbf{x}\), \(\ell_{2}\)-normalized across all atoms:
The numerator is alignment with key \(i\); the denominator stabilizes scale across the memory bank. The paper finds this intrinsic scoring competitive with external routers (their Table 4).
While Eq. (5) measures relevance, naive dense activation leads to low specialization and induces interference and computational overhead; MoRAM therefore uses sparse routing to sharpen the mixture.
Sparse rank selection. To limit interference and cost, we enforce sparsity via top-\(k\) masking: only the \(k\) largest scores stay active; others are masked to \(-\infty\) before softmax so at most \(k\) of the \(r_{t}\) atoms receive gradient.
Sharpness enhancement. To further encourage rank specialization and concentrate the update on the most relevant ranks, mixture weights use temperature-scaled softmax on the masked scores with \(\tau_{\text{MoRAM}}\); lower \(\tau_{\text{MoRAM}}\) sharpens which experts activate in the forward pass and routes gradients more selectively in the backward pass.
Threshold-based expert selection. At inference, a cutoff \(\delta\) on normalized scores filters weak experts among the top-\(k\) set, reducing compute and noise:
This yields a highly sparse, input-dependent set comprising only the most significant memory experts.
X-TAIL is a cross-domain, task-incremental protocol for CLIP-style models: a sequence of image-classification domains. We report Transfer (future domains before training), Average (mean over stages and domains), and Last (all seen domains after the full run)
TRACE benchmarks continual learning in LLMs with eight mixed tasks (e.g. reasoning, summarization, code). We report Overall Performance (OP) after the final task and Backward Transfer (BWT) for forgetting; higher OP and lower BWT are better.
Comparisons on X-TAIL for each domain in terms of Transfer, Average, and Last accuracy (%). Section labels and the rightmost Average column follow the paper. MoRAM rows are highlighted.
| Method | Aircraft | Caltech | DTD | EuroSAT | Flowers | Food | MNIST | OxPet | Cars | SUN397 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP | |||||||||||
| Zero-shot | 23.5 | 76.8 | 37.3 | 36.7 | 63.6 | 84.0 | 46.7 | 86.7 | 66.1 | 63.7 | 58.5 |
| Fine-tune | 39.6 | 84.7 | 70.0 | 94.7 | 97.0 | 85.8 | 97.6 | 93.4 | 81.0 | 74.7 | 81.9 |
| Transfer | |||||||||||
| CLIP zero-shot | — | 76.8 | 37.3 | 36.7 | 63.6 | 84.0 | 46.7 | 86.7 | 66.1 | 63.7 | 62.4 |
| LwF | — | 66.6 | 26.9 | 19.5 | 51.0 | 78.4 | 26.6 | 68.9 | 35.5 | 56.1 | 47.7 |
| WiSE-FT | — | 70.1 | 31.9 | 25.3 | 56.3 | 79.8 | 29.9 | 74.9 | 45.6 | 56.8 | 52.3 |
| iCaRL | — | 71.7 | 35.0 | 43.0 | 63.4 | 86.9 | 43.9 | 87.8 | 63.7 | 60.0 | 61.7 |
| ZSCL | — | 73.3 | 32.6 | 36.8 | 62.1 | 83.8 | 42.1 | 83.6 | 56.5 | 60.2 | 59.0 |
| MoE-Adapter | — | 71.0 | 34.9 | 19.2 | 63.0 | 86.6 | 20.0 | 87.2 | 63.7 | 58.6 | 56.0 |
| RAIL-Primal | — | 76.8 | 37.3 | 36.7 | 63.6 | 84.0 | 46.7 | 86.7 | 66.1 | 63.7 | 62.4 |
| CoDyRA | — | 74.3 | 36.8 | 44.2 | 69.9 | 83.5 | 42.8 | 88.9 | 64.6 | 63.4 | 63.2 |
| MoRAM | — | 74.5 | 38.1 | 46.9 | 65.3 | 82.9 | 45.8 | 88.2 | 65.1 | 62.9 | 63.3 |
| Average | |||||||||||
| LwF | 24.7 | 79.7 | 38.3 | 36.9 | 63.9 | 81.0 | 36.5 | 71.9 | 42.7 | 56.7 | 53.2 |
| WiSE-FT | 27.1 | 76.5 | 40.9 | 31.3 | 68.7 | 81.6 | 31.4 | 74.7 | 51.7 | 58.4 | 54.2 |
| iCaRL | 25.4 | 72.1 | 37.5 | 51.6 | 65.1 | 87.1 | 59.1 | 88.0 | 63.7 | 60.1 | 61.0 |
| ZSCL | 36.0 | 75.0 | 40.7 | 40.5 | 71.0 | 85.3 | 46.3 | 83.3 | 60.7 | 61.5 | 60.0 |
| MoE-Adapter | 43.6 | 77.9 | 52.1 | 34.7 | 75.9 | 86.3 | 45.2 | 87.4 | 66.6 | 60.2 | 63.0 |
| RAIL-Primal | 42.4 | 89.8 | 55.7 | 68.5 | 84.0 | 83.3 | 65.3 | 85.8 | 67.9 | 64.5 | 70.7 |
| CoDyRA | 41.4 | 81.0 | 58.7 | 77.8 | 83.4 | 84.6 | 64.5 | 90.4 | 67.2 | 64.4 | 71.3 |
| MoRAM | 44.1 | 81.6 | 64.6 | 79.6 | 83.9 | 84.4 | 66.5 | 89.7 | 68.4 | 64.1 | 72.7 |
| Last | |||||||||||
| LwF | 25.5 | 72.1 | 38.9 | 55.4 | 65.5 | 87.3 | 81.9 | 88.6 | 63.6 | 61.5 | 64.0 |
| WiSE-FT | 21.8 | 76.8 | 42.9 | 20.8 | 77.5 | 84.9 | 30.7 | 76.6 | 75.8 | 72.5 | 58.0 |
| iCaRL | 25.5 | 72.1 | 38.9 | 55.4 | 65.5 | 87.3 | 81.9 | 88.6 | 63.6 | 61.5 | 64.0 |
| ZSCL | 33.1 | 75.3 | 43.5 | 35.2 | 74.6 | 87.4 | 50.4 | 84.2 | 77.3 | 73.4 | 63.4 |
| MoE-Adapter | 43.2 | 78.7 | 57.6 | 32.8 | 79.4 | 86.0 | 86.7 | 87.8 | 78.2 | 74.2 | 70.5 |
| RAIL-Primal | 41.7 | 94.0 | 66.0 | 86.4 | 97.2 | 82.4 | 93.1 | 83.6 | 75.0 | 71.3 | 79.1 |
| CoDyRA | 37.7 | 81.5 | 65.1 | 89.9 | 91.4 | 85.5 | 96.8 | 93.3 | 77.3 | 73.5 | 79.2 |
| MoRAM | 37.7 | 81.5 | 70.7 | 92.4 | 95.0 | 86.0 | 97.6 | 92.6 | 81.0 | 74.7 | 80.9 |
Comparison on the TRACE benchmark: Overall Performance (OP, higher is better) and Backward Transfer (BWT, lower is better). Values are mean ± standard deviation over three runs. The MoRAM column is highlighted.
| FIX(ICL) | SeqLoRA | OGD | GEM | EWC | L2P | DualPrompt | HiDeLoRA | O-LoRA | TreeLoRA | MoRAM | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| meta-llama / LLaMA-2-7B-Chat | |||||||||||
| OP | 38.94 ± 0.3 | 34.3 ± 1.2 | 42.09 ± 1.6 | 40.08 ± 1.6 | 42.36 ± 1.2 | 36.23 ± 0.8 | 37.69 ± 1.2 | 41.60 ± 0.8 | 42.78 ± 0.8 | 43.52 ± 1.0 | 44.54 ± 0.9 |
| BWT | – | 18.5 ± 0.8 | 8.06 ± 1.2 | 6.77 ± 1.2 | 5.97 ± 0.8 | 8.25 ± 0.8 | 8.03 ± 0.8 | 7.12 ± 0.4 | 7.16 ± 0.4 | 3.46 ± 0.4 | 1.37 ± 0.3 |
| google / Gemma-2B-it | |||||||||||
| OP | 32.3 ± 0.2 | 31.89 ± 0.8 | 32.85 ± 1.4 | 26.48 ± 1.5 | 28.35 ± 1.6 | 31.14 ± 1.2 | 32.42 ± 1.0 | 33.25 ± 0.9 | 33.73 ± 0.8 | 33.41 ± 0.9 | 36.27 ± 0.7 |
| BWT | – | 15.28 ± 0.4 | 12.27 ± 0.9 | 18.25 ± 0.9 | 16.96 ± 1.2 | 15.77 ± 0.7 | 14.25 ± 0.5 | 13.66 ± 0.5 | 12.36 ± 0.4 | 8.50 ± 0.5 | 2.74 ± 0.4 |
| meta-llama / LLaMA-3-1B-Instruct | |||||||||||
| OP | 31.16 ± 0.4 | 29.73 ± 1.6 | 30.12 ± 2.0 | 32.19 ± 2.0 | 31.96 ± 1.6 | 29.38 ± 1.2 | 30.76 ± 1.2 | 33.73 ± 1.2 | 32.94 ± 0.8 | 36.14 ± 0.7 | 37.77 ± 0.8 |
| BWT | – | 17.03 ± 1.2 | 15.2 ± 1.6 | 10.74 ± 1.6 | 11.62 ± 1.2 | 13.57 ± 0.8 | 11.34 ± 0.8 | 12.36 ± 0.8 | 12.89 ± 1.2 | 7.36 ± 0.8 | 3.12 ± 0.8 |
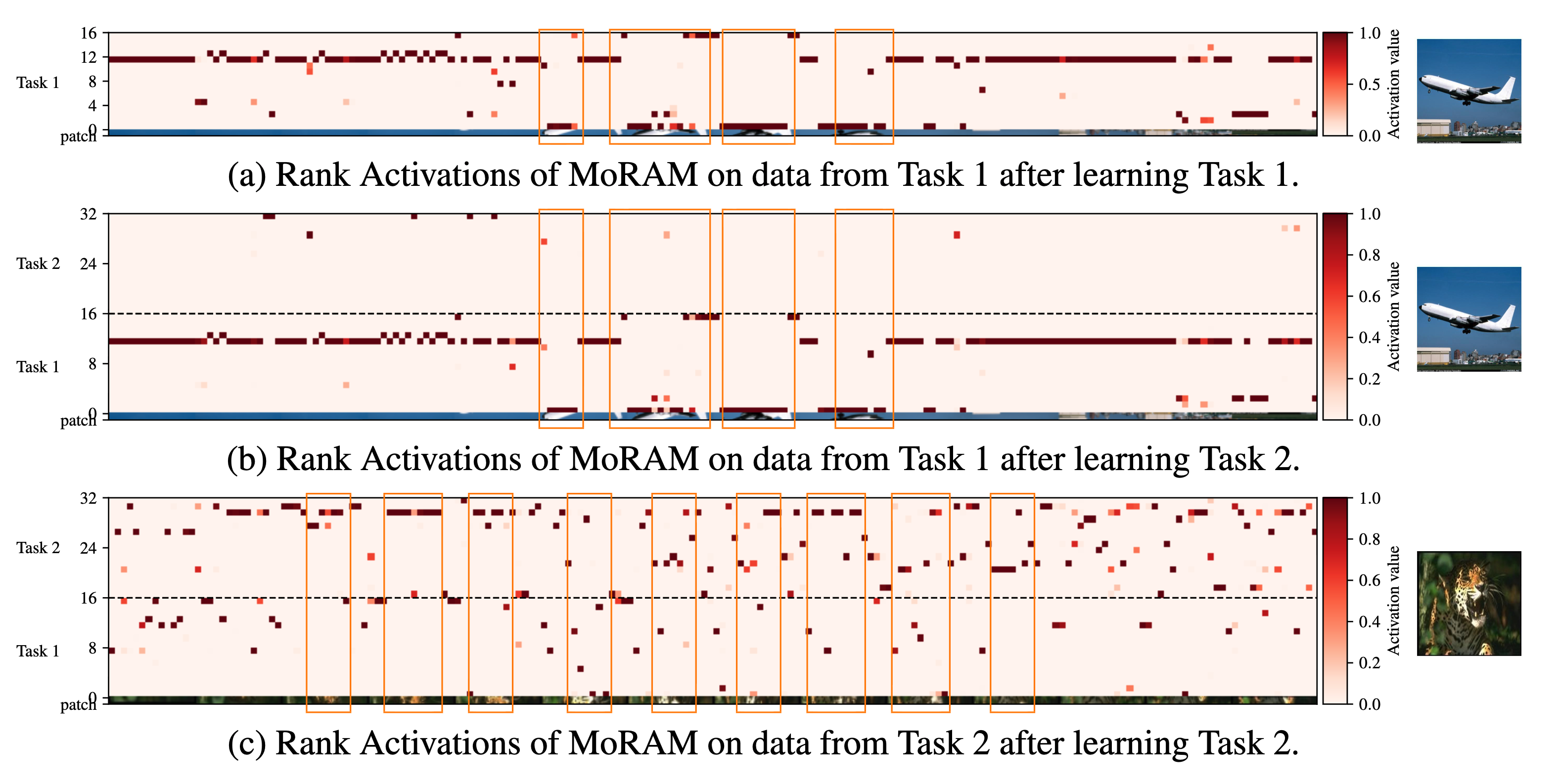
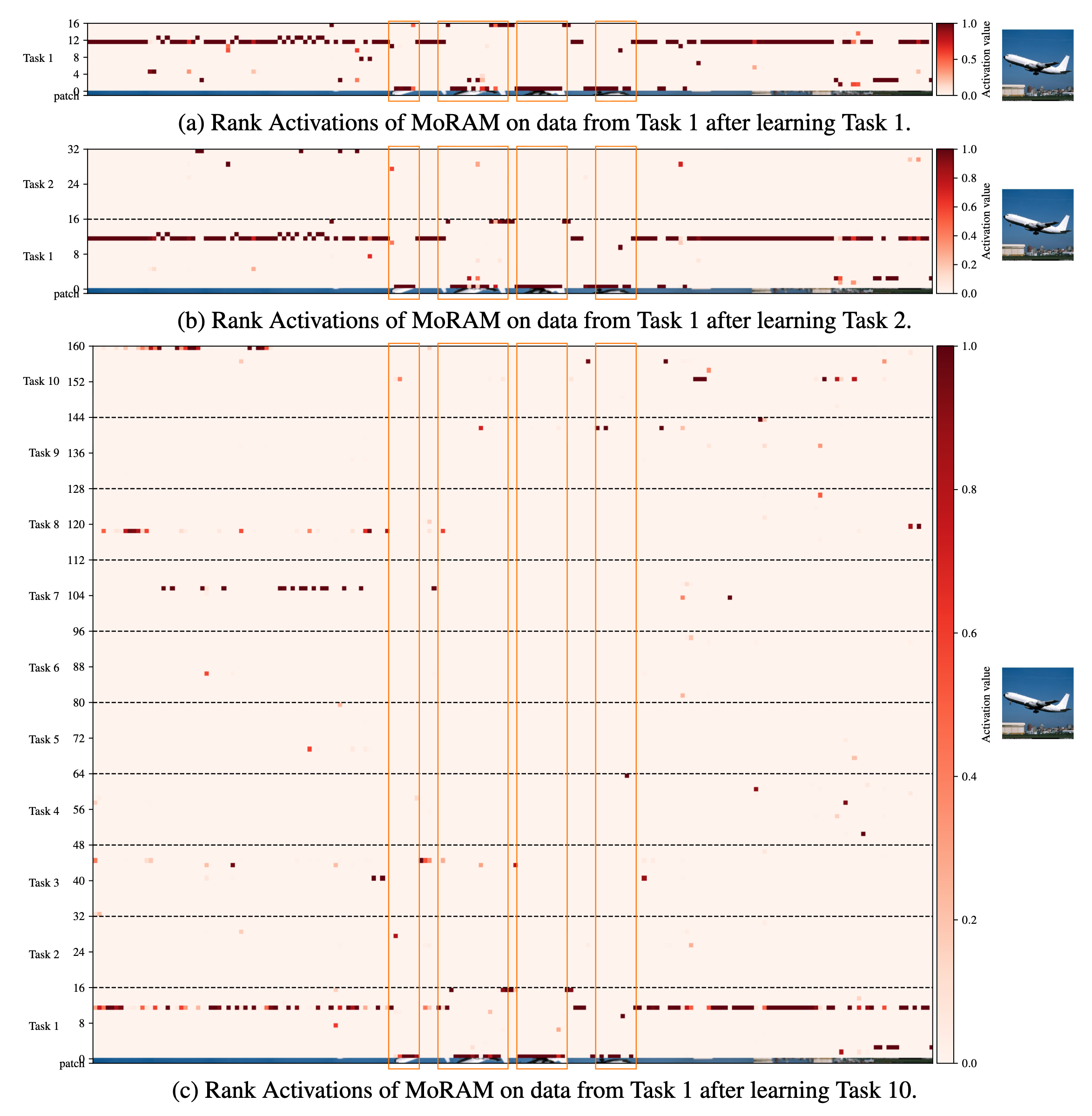
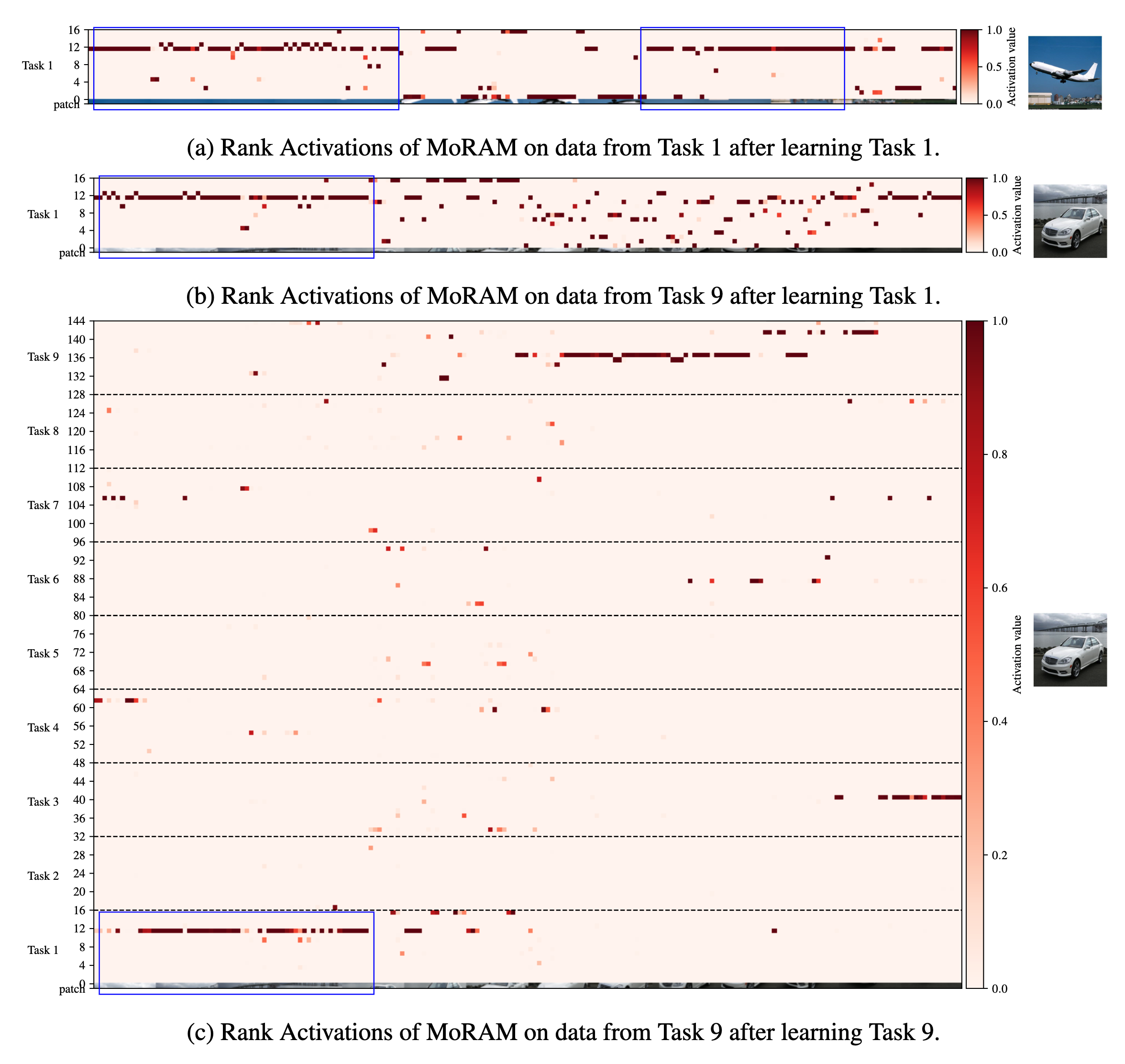
Because MoRAM routes through per-atom mixture weights, we can read off each rank-1 atom’s contribution as a rank activation map: a heatmap whose rows are rank indices (grouped by task, separated by dashed lines) and columns are image patches, with colour intensity proportional to activation value. Maps below are extracted from the \(K\) projection in CLIP’s image-encoder attention (layer 8) during continual fine-tuning on X-TAIL. Coloured boxes highlight semantically informative patch columns. Together the three figures illustrate atom specialization, forgetting mitigation, and knowledge reuse. For full analysis and protocol, see §4.2 and Appendix A.12 in the paper.
(a) Task 1 (Aircraft) input evaluated after learning Task 1 only — 16 ranks available. A handful of ranks (e.g. rank 12) fire strongly on specific patches while others stay near zero, showing clear specialization. (b) The same Task 1 input re-evaluated after Task 2 is added (32 ranks total). Task 1 ranks (1–16) retain virtually the same pattern; the newly added Task 2 ranks (17–32) remain mostly silent — evidence that new capacity does not disturb earlier atoms. (c) A Task 2 input evaluated after learning Task 2. Task 2 ranks now show strong, distinct activations, while some Task 1 ranks also fire where visual patterns overlap, indicating early knowledge reuse. Orange boxes highlight patch columns of interest across panels.
The same Task 1 (Aircraft) input is tracked as the model grows from 16 ranks to 160 ranks over the full 10-task X-TAIL sequence. (a) After Task 1 (16 ranks). (b) After Task 2 (32 ranks). (c) After Task 10 (160 ranks). Despite the memory bank expanding by 10×, Task 1 ranks retain essentially the same activation pattern — strong, consistent firing on the same patch columns across all three snapshots. Ranks from Tasks 2–10 remain largely inactive on Task 1 data, confirming that the freeze-and-expand design prevents cross-task interference even as capacity grows.
Blue boxes trace shared visual structure across domains. (a) Task 1 (Aircraft) data after learning Task 1 — blue boxes mark the patch groups where Task 1 ranks respond most. (b) Later-task data (Cars) evaluated with only Task 1 atoms — Task 1 ranks still fire on patches with comparable spatial structure (e.g. object body, background). (c) Task 9 (Cars) data after learning nine tasks (144 ranks). Task 1 ranks (bottom rows, blue box) still activate on patches that share visual structure with Aircraft, while Task 9-specific ranks handle novel object details. This decomposition — reused atoms for shared patterns, fresh atoms for new concepts — emerges naturally from the self-activation mechanism without any explicit reuse objective.
@inproceedings{lu2026little,
title = {Little By Little: Continual Learning via Incremental Mixture of Rank-1 Associative Memory Experts},
author = {Lu, Haodong and Zhao, Chongyang and Xue, Minhui and Yao, Lina and Moore, Kristen and Gong, Dong},
booktitle = {Forty-third International Conference on Machine Learning},
year = {2026},
url = {https://openreview.net/forum?id=P247k4ELcn}
}